林誠夏顧問/CC Taiwan、鈞理知識產權事務所
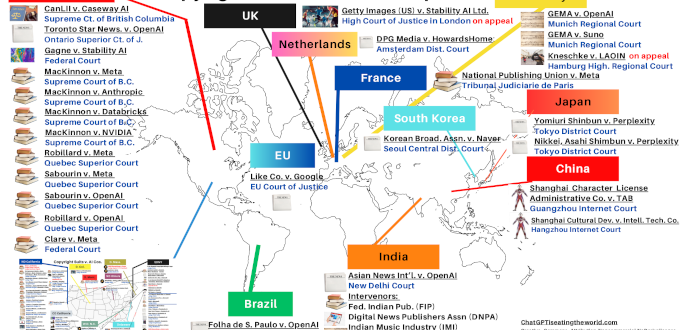
2022年常被戲稱為「AI訴訟元年」。進入2023年後,全球各地更展開激烈的司法攻防,多數案件目前仍在審理中。不過,已有兩個指標性案例值得關注。其一是美國的Bartz v. Anthropic一案。Anthropic於2025年同意支付約15億美元(約每本書3,000美元),與原告作者團體達成和解,以終止因取用盜版書籍資料庫訓練AI所引發的著作權侵權訴訟;其二是德國音樂著作權管理團體提起的GEMA v. OpenAI一案。GEMA指控OpenAI的ChatGPT在訓練過程中侵害歌曲著作權,德國慕尼黑第一地方法院於2025年11月作出實體判決,認定ChatGPT的訓練與輸出行為侵害著作權,並命OpenAI負擔損害賠償責任,此案件仍可能再經上訴。
那麼從這些侵權訴訟案,引出一個重要問題:假設生成式AI工具的提供者,取用他人著作素材來訓練或運用的模式被法院判定侵權,那麼一般消費者或使用者在利用該工具時,是否也可能因此分擔侵權責任?
從法理上來看,著作權侵害原則上仍須建立在「故意或過失」的基礎上。因此,一般消費者的利用行為,未必當然會受到嚴格波及。再從訴訟經濟與實務操作角度觀察,著作權人或其代理組織通常也較不可能對大量的一般使用者逐一提起訴訟。然而,生成式AI在訓練資料的授權基礎上,確實仍存在灰色地帶與法律風險。因此,現階段使用AI工具時,建議遵循以下三項原則:
一、理解「著作權僅保護表達,不保護思想或概念」的基本原則
著作權保障的是具有創作性的「表達」,而非單純的事實或知識本身。因此,若僅是針對單筆或數筆事實資訊進行查詢、整理或分析,不必然需要取得原出處授權,因為這可能僅屬知識學習的範疇。然而,若原出處在資料的選擇與編排上已注入創意,則可能構成著作權法第7條所保護的「編輯著作」。又若AI的產出係基於他人著作的具體表達進行再創作,則可能構成第6條所稱的「衍生著作」。在這兩類情境下,便無法再主張只是「學習內容而未利用原作表達」。
二、選擇在使用條款中提供責任保障的AI工具
目前多數免費AI工具,通常透過免責聲明排除一切擔保責任,亦即使用者須自行承擔法律風險。相對而言,部分商業化AI服務,於其營利範圍內會提供一定程度的責任承擔條款。例如,若使用GitHub Copilot並啟用Duplication Detection Filter(相似性檢測機制),用以檢測生成程式碼與既有他人程式碼的相似度,則未來若發生侵權爭議,付費用戶當有機會聲請GitHub或該服務的供應商,依契約承擔相關的訴訟責任。這類機制,能在一定程度上降低使用者風險。
三、掌握合理使用的界線,並適度標示原出處
標示出處並不當然等於合理使用,但依著作權法第64條,若能以合理方式明示來源,將有助於法院判斷AI的轉化利用與原作之間,在「目的與性質」上是否具有差異。若能證明利用行為具有轉化目的(Transformative Fair Use),且客觀上不致妨礙原著作財產權的正常行使,則即使未經授權,也可能依照著作權法第65條來排除侵權責任。
整體而言,生成式AI的技術應用與法律風險仍在演變之中。對一般使用者而言,避免使用不是正向的態度,但應理解法律邏輯、選擇風險較低的工具,並謹慎掌握表達與知識的界線,簡言之,他人的獨特表達是需要尊重的,然廣域的知識資訊則是可以學習的。
No Comments Yet